

Narrative Science,一家致力于让机器写作的公司

【摘要】在现实的商业环境中,对一项创新技术或某些产品而言,要达到有效的专利保护,形单影只的单项专利总是有自身的局限性,要打破这种局限,就需要一个专利组合或专利集群,这些专利在技术点上应有差别但又互相关联,在申请时机上应有承接但又避免互相影响,在竞争对手觊觎和挑衅时,这些专利能够互相协同和支持,以此形成合力进而实现有效地保护。
Narrative Science,一家致力于让机器写作的公司
▼
by
德理达-智能制造团队
语言是实施通信的必要手段,在实际应用中,人类通过自然语言进行沟通,计算机采用机器语言识别指令。然而,伴随着人工智能的提出,采用自然语言与计算机进行通信成为人们所追求的目标。
在AI领域中,自然语言处理(Natural Language Processing, NLP)技术成为实现人与计算机之间自然语言通信的基础,而实现人机间自然语言通信一方面要使计算机能够理解自然语言文本的意义,另一方面也要使计算机能够以自然语言文本来表达给定思想,前者称为自然语言理解(Natural Language Understanding,NLU),后者称为自然语言生成(Natural Language Generation,NLG)。
具体地,自然语言理解NLU的目标是使计算机能够像人一样进行阅读,其常见应用例如机器翻译、语音识别;自然语言生成NLG则关注的是使计算机具有人一样的表达和写作能力,其常见应用例如机器写作。

基于计算机擅长数据分析,人类倾向于阅读故事的事实,如何将数据变成叙述性文本而不仅是基于数据的简单拼凑是自然语言生成技术的核心所在。
本次介绍的Narrative Science公司正是一家以赋予数据生命为宗旨的文本输出公司,其致力于研究根据一些关键信息及其在机器内部的表达形式,经过一个规划过程,自动生成一段高质量文本的技术,为未来写作定义了新的模式——机器创作。
▼
Narrative Science,基于自然语言处理的拟人化文本输出方
Narrative Science是由美国西北大学的Kris Hammond教授和Larry Birnbaumn副教授于2010年在芝加哥成立的自然语言处理服务公司,其创办灵感来源于西北大学创新实验室里的人工智能技术——StatsMonkey(统计猴)。
StatsMonkey是一款专用于撰写体育赛事报道的软件,该软件能够抓取比赛的数据信息并生成一篇既有比赛记录也有关键时段和关键人物介绍的生动的新闻故事。
基于此,Narrative Science发展初期多应用于媒体报道,此后,Narrative Science不断扩张业务版图,其业务重心由媒体转向企业用户,方向为基于海量数据的更加拟人化的文本输出。
Narrative Science的产品
Narrative Science的产品包括Quill(Quill将大量数据转换成文字浅近的“故事”,并凸显最重要的洞见;Quill英文原意是鹅毛笔)和Dynamic Narratives。
其中,Quill是一种高级NLG平台,该平台可以对结构化数据进行分析,理解这些数据的重要性,最终将数据转化为智能且富有洞察力的自然语言,并对与主体相关的其他信息进行充分地展示、聚合,为分析决策提供完整透明度的依据。
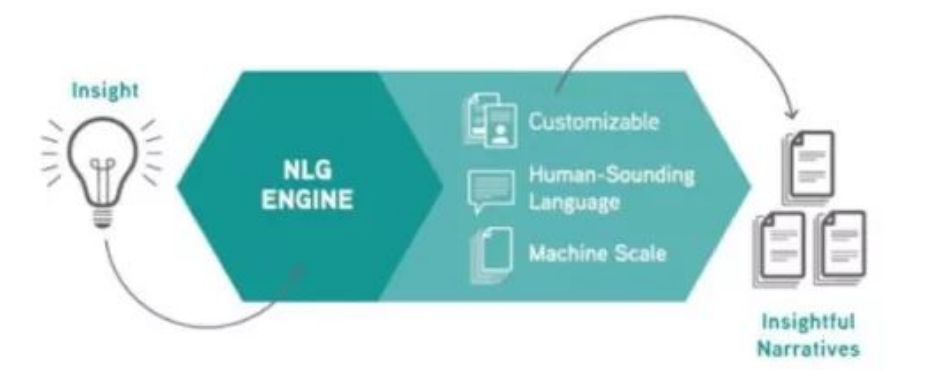
Quill的工作流程图
截至2017年4月,Narrative Science共完成6轮共计为3240万美元的融资,与瑞士信贷、福布斯(Forbes)以及美国政府部门在内的机构建立了合作关系。
▼
Narrative Science的专利保护
和其他科技型创业公司一样,Narrative Science自成立伊始就积极地申请专利以保护自有的创新技术。截止成文前,Narrative Science在美国共公开了20件专利申请,其中,19件专利已授权,1件尚处于实质审查阶段,如此之高的授权率也一定程度上说明了Narrative Science公司研发的技术具有较高的创新水平。
Narrative Science的专利申请策略
基于对Narrative Science专利数据的分析,与本系列已经提及的其他创业公司相同的是,Narrative Science每年都有一定数量的专利申请,未曾间断;但与本系列已经提及的其他创业公司不同的是,Narrative Science似乎更倾向于采用同日递交多件相似专利申请的策略。
例如,Narrative Science于2010年5月13日递交申请的3件相似专利:
US8688434B1,涉及使用数据自动生成叙述性故事的方法和系统;
US8355903B1,涉及使用数据和角度自动生成叙述性故事的方法和系统;
US8374848B1,涉及使用数据和导出特征自动生成叙述性故事的方法和系统。
以两项获得授权的专利US8355903B1和US8374848B1为例,二者独立权利要求中微小差异仅在于技术特征“导出特征(derived feature)”所带来的二者整体技术方案的区别,这种专利组合的申请策略常见于资金充盈及专利密集的大型科技公司。

此外,Narrative Science后期递交的专利申请也大多数要求前期申请的优先权,且对于要求相同优先权的申请多数采用同日递交的策略:
例如2011年7月19日递交3件专利申请:US8892417B1、US8775161B1以及US8886520B1,这一专利组合涉及用于触发自动生成记叙文技术,上述专利皆以2011年1月7日的申请为优先权。
再例如,Narrative Science于2014年10月22日递交1件专利申请:US9720899B1,涉及使用通信目标和叙述分析基于数据自动生成记叙文的专利组合。
同年12月15日,以上述专利申请为优先权,递交2件专利申请:US9977773B1和US9697492B1,这两项专利均涉及使用通信目标和叙述分析基于数据自动生成记叙文的方法。
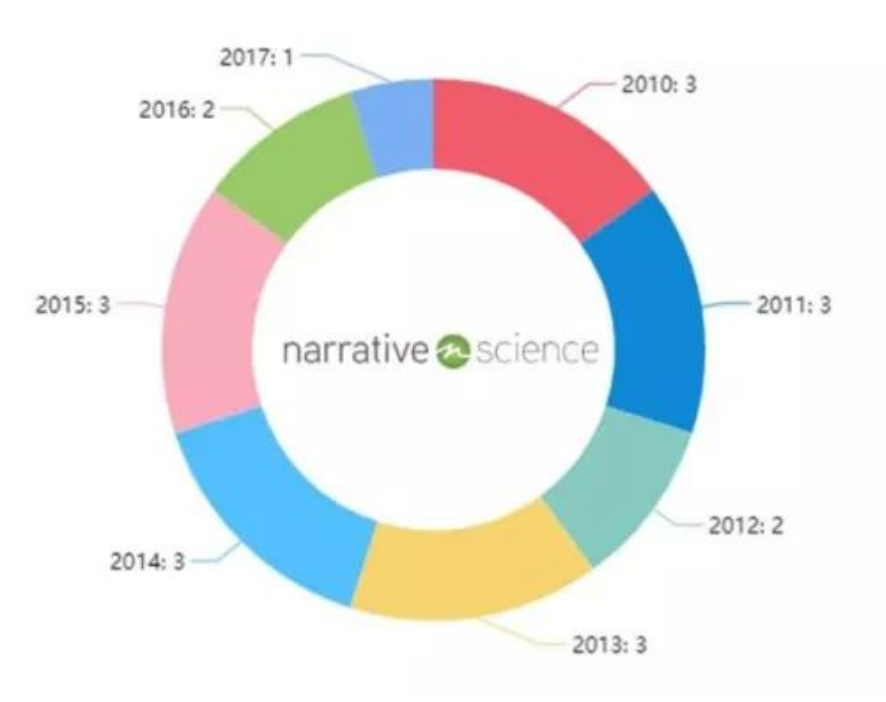
基于上述可知,Narrative Science在专利申请方面有一定的系统规划,比如相近技术的专利采用同日递交,后续申请多以其在先申请为优先权的申请策略,充分围绕相似技术打造专利组合。
▼
专利申请策略之专利组合
诚如我们所观察的情况,许多创业者都十分积极地对倾注了心血或赖以为命的研发成果申请专利保护,但由于创业者的有限精力和公司初创期的条件限制(比如成本和人力资源的配置),这些创业者们常会忽略专利组合的规划。
在现实的商业环境中,对一项创新技术或某些产品而言,要达到有效的专利保护,形单影只的单项专利总是有自身的局限性,要打破这种单兵作战的局限,就需要一个专利组合或专利集群。
这些专利在技术点上应有差别但又互相关联,在申请时机上应有承接但又避免互相影响,在竞争对手觊觎和挑衅时,这些专利能够互相协同和支持,以此形成合力进而实现有效地保护。
▼
百舸争流,结构化数据的叙述者们
鉴于对基于数据以自然语言输出人性化文本以便于读者阅读理解的需求,涌现出一批致力于研究基于海量数据输出高质量文本的自然语言生成公司。
Automated Insights
公司总部位于美国北卡罗来纳州的Automated Insights(原名Stat Sheet)最初在撰写媒体报道方面是Narrative Science最强有力的竞争对手,与Narrative有不少重叠之处。
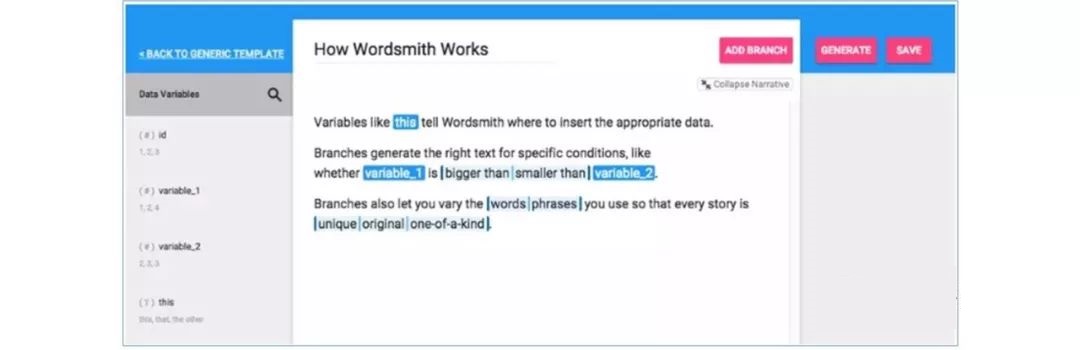
现今,Automated Insights的服务目标主要为小型报刊杂志,此外也涉足体育新闻报道。Automated Insights的自然语言生成平台Wordsmith可将原始数据自动转换为有深度、有个性并且像人类写手那样风格多变的叙事文章。
文因互联
文因互联是2013年建于美国硅谷的、用人工智能解决金融数据分析问题的创业公司,该公司的核心技术是利用知识图谱技术对金融数据进行结构化提取和智能化分析。公司产品文因助手用于提供自动化公告摘要、自动化研报摘要、自动化报告写作等。
其他平台
此外,国内一些互联网公司也相继推出了一系列写作机器人,如腾讯Dreamwriter,今日头条xiaomingbot、第一财经DT稿王、百度Writing-bots等。
上述各公司及平台就各自采用的自动写作技术也相应申请有专利,例如Automated Insights涉及动态生成并呈现叙事内容的技术,文因互联涉及摘要、报告生成的技术,腾讯涉及智能撰文、内容抽取、要闻萃取的技术等。
当然,科技的发展也会带来人们对行为规则和社会法律的讨论,比如,利用人工智能技术实现的机器人作品,其知识产权的归属如何界定,这些都是有意思的话题。
* 以上文字仅为促进讨论和交流,不构成法律意见或咨询建议。
